
개요
작년 6월, Next.js App Directory를 도입하여 RSC로 서비스를 개선한 후 가장 만족스러웠던 기능은 fetch revalidate 옵션을 활용한 데이터 캐시였습니다. revalidate 하기 전까지 캐시된 데이터를 활용함으로써 서버 자원 사용을 획기적으로 줄일 수 있었죠.
하지만 한 가지 아쉬운 점은 캐시 데이터가 서버 인스턴스(프론트) 간에 공유가 되지 않아 발생하는 문제입니다. 이 글에서는 캐시 공유가 안되는 문제와 원인, 대응 전략 그리고 공유 캐시가 필요한 이유에 대해 알아봅니다.
캐시 공유가 안되는 이유와 문제점
캐시 공유가 안되는 근본적인 이유는 Next.js의 캐시 전략에 있습니다. Next.js의 캐시 전략을 간단히 알아보고, 멀티 인스턴스 환경에서 캐시 공유가 안되면 발생하는 문제에 대해 알아봅니다.
Next.js의 캐시 전략
Next.js는 기본적으로 데이터 캐시든 라우트 캐시든 file system 캐시 전략을 이용해 In Memory 방식으로 저장합니다. ( 내부 구현 )
간단하게 확인해 볼 수 있는데요, build 후 .next / cache / fetch-cache 폴더에서 캐싱 된 file을 확인할 수 있습니다.  캐시 된 데이터가 없다면 production 모드로 서버로 실행시킨 후, 페이지를 이동하며 data fetch를 실행해 보세요.
캐시 된 데이터가 없다면 production 모드로 서버로 실행시킨 후, 페이지를 이동하며 data fetch를 실행해 보세요. Cache Miss -> fetch -> Cache Set 순서로 새롭게 file이 쌓이는 걸 볼 수 있습니다. 내부의 file을 모두 제거한다 해도 위와 같은 순서로 다시 쌓이게 됩니다. 
이 방식은
generateStaticParams를 이용해 build 시 캐싱 하지 않을 때 테스트를 해볼 수 있습니다.내부 값을 code beautify에서 확인, body 값도 decode site에서 확인해 볼 수 있습니다. 내부 값의
"kind": "FETCH"를 통해 fetch( data cache )에 해당하는 캐시임을 확인할 수 있습니다.

로드 밸런서와 멀티 인스턴스에서의 문제점
제가 개발하고 있는 서비스는 평시 5대 정도의 인스턴스를 운영하고, 로드 밸런서를 통해 트래픽을 분산합니다. 클라이언트 요청이 들어오면, 로드 밸런서를 이용해 적절한 인스턴스로 접근합니다. 이때 In Memory 캐싱 전략에서는 캐시된 데이터가 공유되지 않아 데이터 일관성 문제가 발생합니다.
1. 데이터 업데이트 후, A 인스턴스로 첫 진입해 revalidate 요청. 업데이트되기 전 데이터 노출 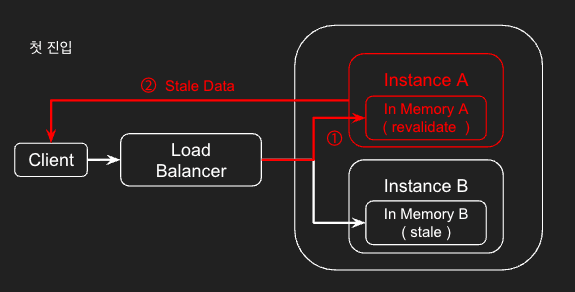
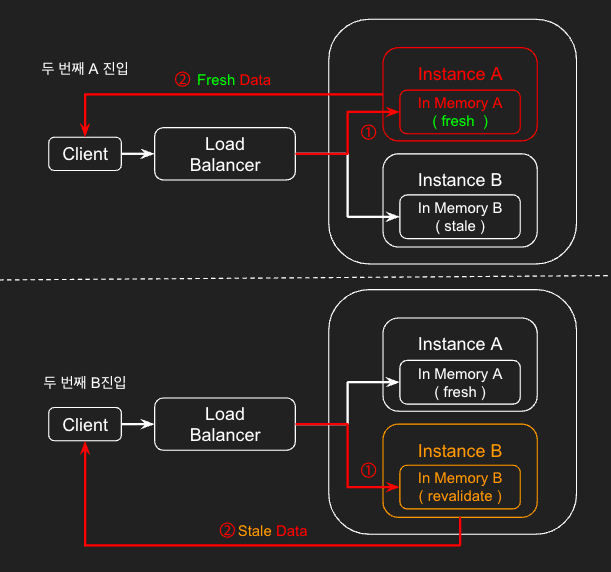
2. 두 번째 진입 시, 접근하는 인스턴스에 따라 fresh, stale 데이터를 노출 ( 문제점 )
임시 대처와 캐시 공유의 필요성
위에서 언급한 문제점은 그동안 Time Base Revalidation을 이용해 임시로 대처했습니다. 사실 업데이트되는 데이터는 크리티컬한 데이터는 아닙니다. 오타 정도 되는 데이터인데요, revalidate time 만큼 기다릴 수 있었고, 초당 트래픽을 고려했을 때 알아서 모든 인스턴스에 접근해 업데이트될 수 있도록 설계를 했습니다.
크리티컬한 데이터인 경우는 항상 최신 데이터를 받도록 설계되어 있습니다.
Time Base Revalidation의 문제점
기획, 정책에 따라 캐시가 공유되지 않는 문제를 Time base revalidation로 non issue로 처리할 수 있겠지만, 이상적인 방식은 아닙니다. 이 경우 다음과 같은 불편함이 있을 수 있습니다.
1. revalidate time 만큼 발생하는 요청
현재 설정된 5분 주기로 revalidate가 수행되면, 초당 트래픽이 일정하게 발생한다고 가정할 때 하루에 288번의 API 호출이 발생합니다.
2. 데이터 확인 과정
데이터를 수정한 관리자가 변경 사항을 확인하려면 revalidate가 실행되기를 기다려야 합니다. 5분이라는 주기로 인해 최악의 경우 5분 동안 대기해야 하는 상황이 발생하며, 이는 효율성을 떨어뜨립니다. 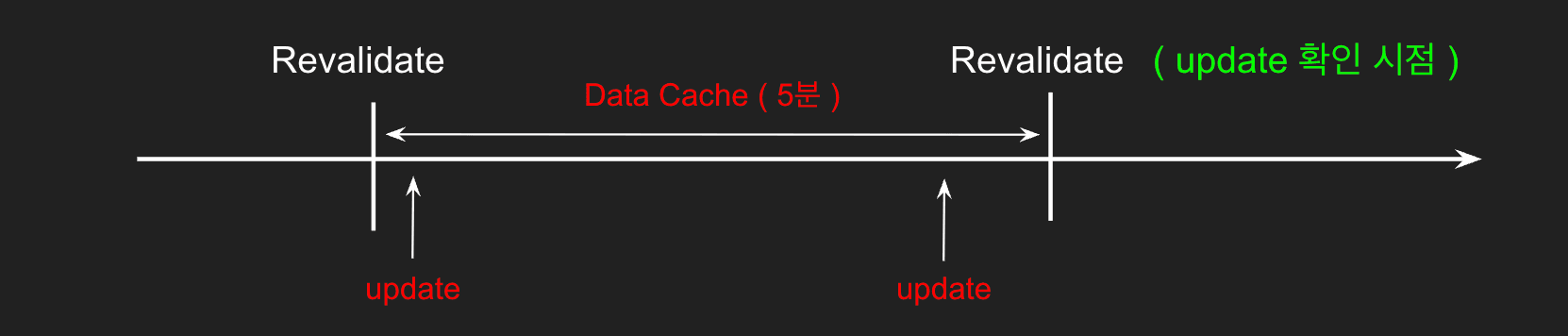
On Demand Revalidation 방식과 문제점
Time base 방식의 문제점은 On Demand 방식으로 해결할 수 있습니다. time 주기마다 revalidate를 실행하는 게 아닌, trigger가 발생하면 revalidate 하는 방식입니다. 따라서 API 호출도 1번, 데이터 확인도 거의 즉시 확인할 수 있습니다.
가장 이상적인 방식 같지만, 멀티 인스턴스 환경에서 큰 약점이 드러납니다. 다음과 같은 상황을 고려해 봅니다.
1. A 인스턴스에 진입한 상태에서 On Demand로 revalidate 실행 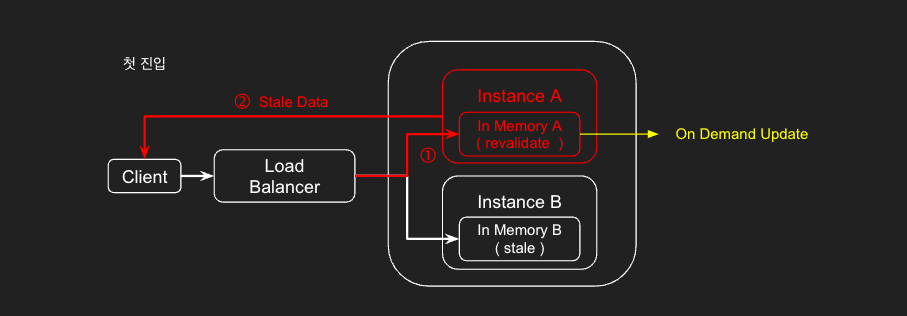
2. 두 번째 진입 시 A 인스턴스는 fresh 데이터를, B 인스턴스는 revalidate 되지도 않은 채 유지 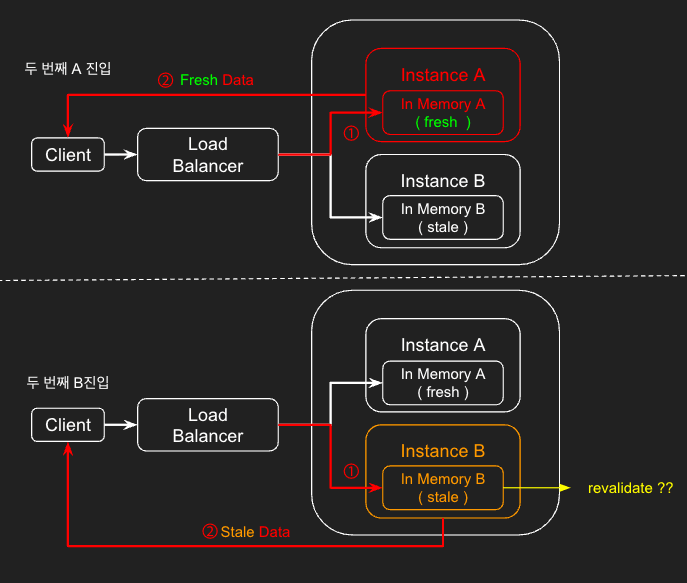
이 방식의 문제점은 각 인스턴스에서 일일이 revalidate를 진행해야 한다는 겁니다. 또, 인스턴스가 점점 scale out 되면 그만큼 회수도 늘어나고, 무엇보다 어느 인스턴스에 진입할지 모르는 상태에서 데이터를 비교해 stale 인스턴스를 찾고 진행해야 합니다.
캐시 공유의 필요성
On Demand의 문제점들은 사실상 도입이 불가능했습니다. Time Base 방식은 인스턴스에 접근했을 때 stale 상태라면 revalidate를 알아서 진행하지만, On Demand 방식은 수동으로 인스턴스를 찾고 revalidate를 시켜줘야 하니깐요.
이제 On Demand의 trigger를 인스턴스 수만큼 하는 게 아닌 한 번만 할 수 있도록 캐시 공유의 필요성을 생각합니다. ( 다음 글에 이어집니다. )